ボルツマン分布はどうして指数関数になるのか?数値シミュレーションで確かめてみた
Table of Contents
エネルギー分布の謎とボルツマン分布
理想気体では、粒子が激しく熱運動しながら、互いに衝突してエネルギーを交換し合います。では、多数の気体粒子のエネルギーはどのように分布しているのでしょうか?
この分布は正規分布のような綺麗な釣鐘型にはならず、エネルギーが低い粒子が圧倒的多数を占め、ごく一部の粒子だけが高いエネルギーを持つ、という特徴的な形になります。
この分布はボルツマン分布として知られ、綺麗な指数関数で記述できます。では、なぜこのような偏りが生まれるのでしょうか?
実はこの現象、たくさんの粒子がエネルギーという「富」をランダムに交換しあった結果生まれる、最も自然で「ありふれた」状態だと理解することができます。。
この記事では、この一見すると不思議な現象が、なぜ単純な指数関数で表せるのか。その謎を解き明かすため、簡単な 「チップ交換ゲーム」 のモデルを使い、Pythonでシミュレーションしてその本質に迫ります!
ボルツマン分布はなぜ指数関数になるのか
統計力学でボルツマン分布を勉強した際、抽象度が高く理解に苦しんだ方も少なくないと思います。もしくは、演習問題を解く上でボルツマン分布は使えても、どうしてボルツマン分布が指数関数になるのかを説明するのは難しいと思います。
この文章では、ボルツマン分布に従う系の特徴を捉えたモデルを構築し、数値実験することで指数関数が再現されることを実験的に理解してみたいと思います。あくまで直観的な理解になるので、厳密な証明というよりかは実験的な理解の範疇だと思って頂ければと思います。
理想気体
ボルツマン分布に従う最もシンプルな系は理想気体です。理想気体中の分子は縦横無尽に熱運動しており、各粒子が持っているエネルギーの値はまちまちです。しかし、少ないエネルギーを持つ粒子が系の大多数を占め、大きなエネルギーを持つ粒子はごく少数であろう ことは予想できます。理想気体が他の系とエネルギーのやり取りをしない断熱容器に入れられているなら、理想気体の粒子が持つエネルギーの総量は一定だからです。
エネルギーを持つ粒子の数をとします。ボルツマン分布によると、逆温度を持つ系では
となることが知られています。が指数関数になることを理解すべく、理想気体の特徴を考えてみます。
理想気体の特徴(1):孤立系
上記でも述べましたが、理想気体は外部とエネルギーのやり取りをしない孤立系です。つまり粒子数と総エネルギーは一定の値をとります。そのため、各粒子に総エネルギーが分配されて、一粒子ごとに平均程度のエネルギーを有することになります。
理想気体の特徴(2):粒子同士は衝突を繰り返す
理想気体の粒子は互いに衝突し合います。その際に、系の構成要素である粒子がエネルギーを授受しあいます。こうして粒子一つ一つが持っているエネルギーに揺らぎが生じ、だんだん粒子の持つエネルギーの値が平均化されていきます。
この点が非常に重要で、ボルツマン分布が登場するカノニカル統計では、系の構成要素同士で弱いエネルギーの相互作用を行います。以下の議論では、粒子間の衝突を相互作用とみなし、相互作用に伴いエネルギーを交換することをモデルに組み込みます。
理想気体の特徴(3):(2)を繰り返すと熱平衡状態に至る
粒子同士が衝突する前では、高エネルギーの粒子も低エネルギーの粒子も混在しているかもしれません。しかし、粒子同士の衝突を繰り返すことで、高エネルギーの粒子は低エネルギーの粒子にエネルギーを分け与えるイベントが繰り返し生じます。したがって、(2)が繰り返されると粒子のエネルギーが平均化され続けて熱平衡状態に至ります。熱平衡状態では、高エネルギーの粒子がごくわずかで、低エネルギーの粒子が系の大多数を占めるであろうことが予想できます。
以上をまとめましょう。
(1) 総粒子数 、総エネルギー量 は一定。
(2) 2粒子の衝突でエネルギーを授受する。
(3) (2)を繰り返すと熱平衡状態に至る。
モデル化
前節で抽象した理想気体の特徴をモデル化しましょう。
6人で30枚のチップを適当に分配します。次に、6人から無作為に2人選び、片方からもう片方にチップを1枚譲渡します。この操作を何回も繰り返します。持っているチップの枚数でヒストグラムを作成するとどうなるでしょうか。
ただし、チップが0枚の人からはチップを奪いません。借金は無しとします。
(1) 6人で30枚のチップを分配する。
(2) 2人を選び、チップを1枚ずつ授受する。
(3) (2)を何度も繰り返す。
理想気体の特徴と比較しましょう
(1) 6人30枚のチップ 粒子数、エネルギーの系
(2) 2人でチップの授受 2粒子衝突でエネルギーの授受
(3) 授受を繰り返す 衝突を繰り返す
人数が粒子数、チップがエネルギー、チップの授受が衝突に対応します。
実装
統計的に見るために、この6人グループを100グループ作成します。
import numpy as np
import matplotlib.pyplot as plt
import random
from scipy.optimize import curve_fit
def initial_distribution(num_people, num_chips):
"""
チップを初期状態としてランダムに分配します。
Args:
num_people (int): 人数。
num_chips (int): チップの総数。
Returns:
np.ndarray: 各人が持つチップの枚数を格納した配列。
"""
boxes = np.zeros(num_people, dtype=int)
for _ in range(num_chips):
target_box = random.randint(0, num_people - 1)
boxes[target_box] += 1
return boxes
def give_and_take(boxes):
"""
2人をランダムに選び、片方からもう片方へチップを1枚渡します。
Args:
boxes (np.ndarray): 各人が持つチップの枚数を格納した配列。
Returns:
np.ndarray: チップ交換後の配列。
"""
num_people = len(boxes)
new_boxes = boxes.copy()
# 交換する2人(Aさん、Bさん)を重複なく選ぶ
giver_A, receiver_B = random.sample(range(num_people), 2)
# Aさんがチップを持っていれば、Bさんに1枚渡す
if new_boxes[giver_A] > 0:
new_boxes[giver_A] -= 1
new_boxes[receiver_B] += 1
return new_boxes
def exp_func(x, A, beta):
"""
フィッティング対象の指数関数 y = A * exp(-beta * x)
"""
return A * np.exp(-beta * x)
# --- 1. シミュレーションの実行 ---
# パラメータ設定 (元記事のJuliaコードに準拠)
num_people = 6
num_chips = 30
num_groups = 100
num_iterations = 500 # チップの交換回数
print("シミュレーションを開始します...")
# 100グループの初期状態を作成
total_boxes = np.array([initial_distribution(num_people, num_chips) for _ in range(num_groups)])
# 全グループで、チップの交換を500回繰り返す
for i in range(num_iterations):
if (i + 1) % 100 == 0:
print(f" イテレーション: {i + 1}/{num_iterations}")
for j in range(num_groups):
total_boxes[j, :] = give_and_take(total_boxes[j, :])
print("シミュレーションが完了しました。")
# --- 2. 指数関数フィッティング ---
print("指数関数フィッティングを開始します...")
# ヒストグラムの生データを取得
final_distribution = total_boxes.flatten()
max_chips_observed = int(np.max(final_distribution))
bins = np.arange(0, max_chips_observed + 2)
counts, bin_edges = np.histogram(final_distribution, bins=bins)
bin_centers = (bin_edges[:-1] + bin_edges[1:]) / 2
# 度数が0の点はフィット計算から除外
x_data = bin_centers[counts > 0]
y_data = counts[counts > 0]
# 最適なパラメータ(popt)を求める
popt, pcov = curve_fit(exp_func, x_data, y_data, p0=[100, 0.2])
A_fit, beta_fit = popt
print(f"フィッティング結果: A = {A_fit:.2f}, beta = {beta_fit:.2f}")
# --- 3. 結果の描画 ---
print("グラフを生成しています...")
plt.style.use('seaborn-v0_8-whitegrid')
fig, ax = plt.subplots(figsize=(10, 6))
# シミュレーション結果を棒グラフでプロット
ax.bar(bin_centers, counts, label='Simulation Data (Histogram)')
# フィッティングした指数関数を曲線でプロット
x_fit = np.linspace(0, max_chips_observed, 200)
ax.plot(x_fit, exp_func(x_fit, A_fit, beta_fit), 'r-', lw=2,
label=f'Fitted Curve: $A e^{{-\\beta x}}$\n$A={A_fit:.2f}, \\beta={beta_fit:.2f}$')
# グラフの装飾
ax.set_title('Exponential Fit to Simulation Data')
ax.set_xlabel('Number of Chips')
ax.set_ylabel('Frequency (Number of People)')
ax.legend()
ax.set_xlim(left=-1)
ax.set_ylim(bottom=0)
# グラフをファイルに保存して表示
plt.savefig('boltzmann_simulation_and_fit.png')
plt.show()
print("\n処理が完了しました。結果のグラフは 'boltzmann_simulation_and_fit.png' として保存されました。")
実装結果
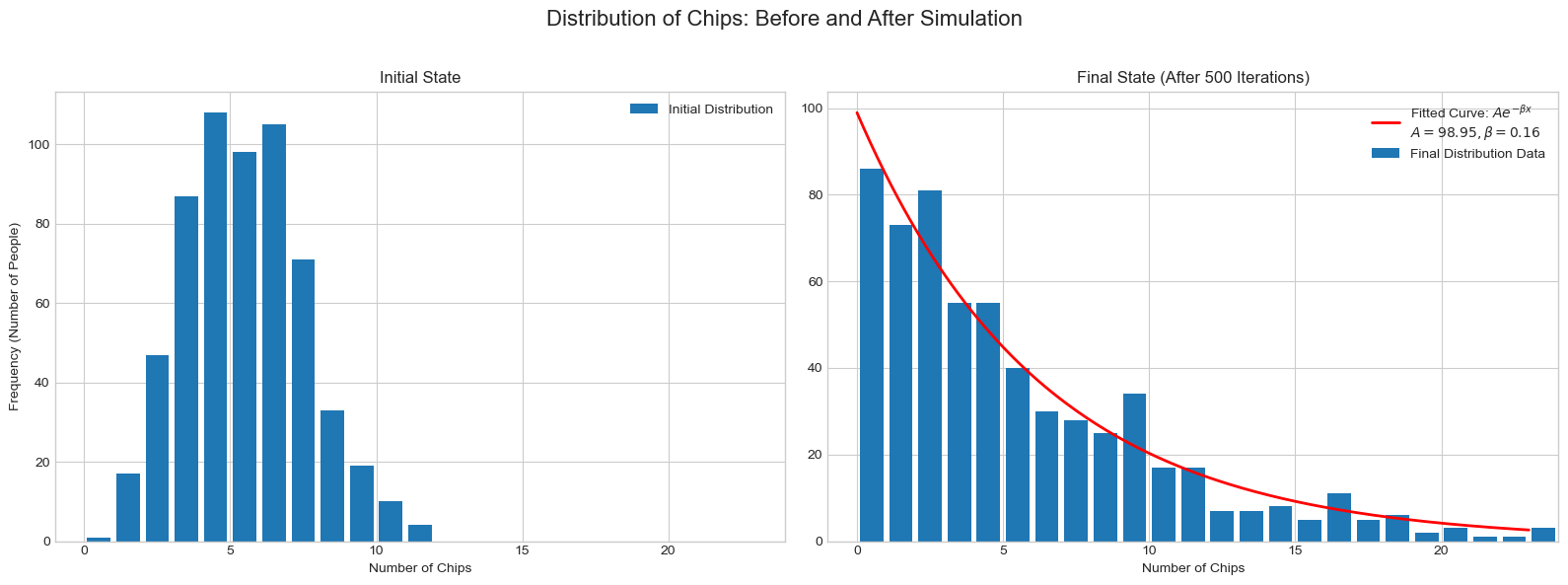
横軸がチップの枚数で、縦軸がそのチップ数を持つ人数を表しています。以上のように、指数関数に非常に近い結果が実験的に導かれていることが確かめられます。このように、チップの授受が可能であることが指数関数を導く鍵になっているようです。
指数関数的に減少することは、たくさんのチップを有する人の割合が非常に少ないことを表しています。十分量の試行回数があるとき、ある1人がチップを枚増やすためにはM回抽選に選ばれての確率で勝利し続けなければなりません。その勝率はに比例するため、そのような豪運の持ち主は指数関数的に減少するのだと考えられます。
盛者必衰の法則
所持チップ数の時間遷移も見てみましょう。
import numpy as np
import matplotlib.pyplot as plt
import random
def initial_distribution(num_people, num_chips):
"""
チップを初期状態としてランダムに分配します。
"""
boxes = np.zeros(num_people, dtype=int)
for _ in range(num_chips):
target_box = random.randint(0, num_people - 1)
boxes[target_box] += 1
return boxes
def give_and_take(boxes):
"""
2人をランダムに選び、片方からもう片方へチップを1枚渡します。
"""
num_people = len(boxes)
new_boxes = boxes.copy()
giver_A, receiver_B = random.sample(range(num_people), 2)
if new_boxes[giver_A] > 0:
new_boxes[giver_A] -= 1
new_boxes[receiver_B] += 1
return new_boxes
# --- シミュレーションのパラメータ設定 ---
num_people = 6
num_chips = 30
num_iterations = 600 # 時間ステップの総数
# --- 時間変化の記録 ---
print("時間変化のシミュレーションを開始します...")
# 各時間ステップでのチップ数を記録する配列を準備
# (行: 時間ステップ, 列: 各個人)
time_dependent_boxes = np.zeros((num_iterations, num_people), dtype=int)
# ステップ0: 初期分布を設定
time_dependent_boxes[0, :] = initial_distribution(num_people, num_chips)
# ステップ1以降: チップ交換を繰り返す
for t in range(1, num_iterations):
# 直前の状態から次の状態を計算
time_dependent_boxes[t, :] = give_and_take(time_dependent_boxes[t - 1, :])
print("シミュレーションが完了しました。")
# --- グラフの描画 ---
print("グラフを生成しています...")
plt.style.use('seaborn-v0_8-whitegrid')
fig, ax = plt.subplots(figsize=(12, 7))
# 各個人のチップ数の時間変化をプロット
for i in range(num_people):
ax.plot(time_dependent_boxes[:, i], label=f'Person {i+1}')
# グラフの装飾
ax.set_title('Time Evolution of Chip Counts for Each Person')
ax.set_xlabel('Time (Number of Iterations)')
ax.set_ylabel('Number of Chips')
ax.legend(title='Person')
ax.grid(True, linestyle='--', alpha=0.6)
ax.set_xlim(0, num_iterations)
ax.set_ylim(bottom=0)
# グラフをファイルに保存して表示
plt.savefig('time_evolution_of_chips.png')
plt.show()
print("\n処理が完了しました。時系列グラフは 'time_evolution_of_chips.png' として保存されました。")
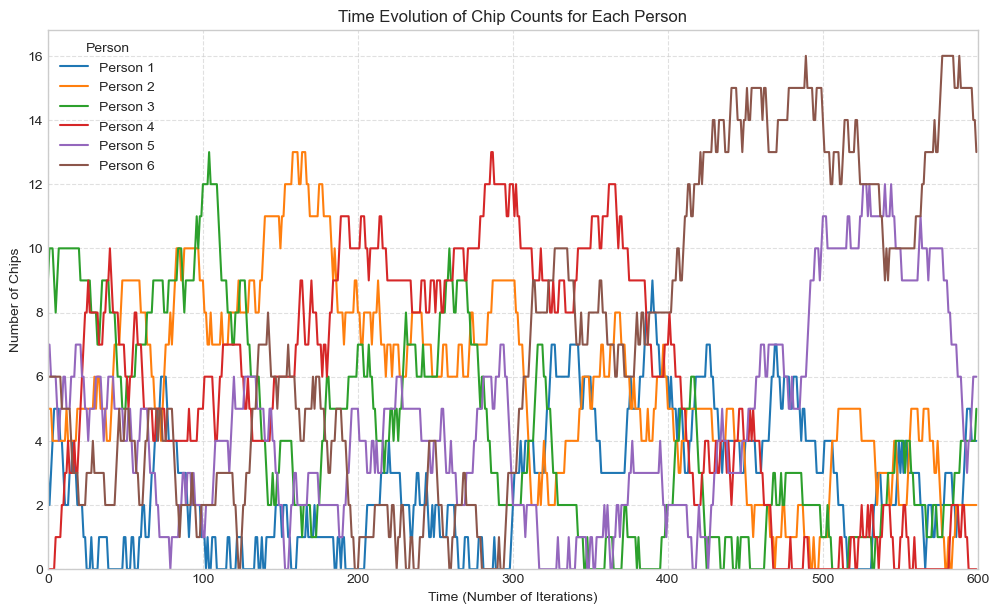
大体の場合には途中でチップを失ってしまいます。この状況を時系列データでプロットすると、一度大富豪になった人が短時間でチップを失う様子が観察されます。筆者は勝手にこの現象を「盛者必衰」と呼んでいます(笑)。
エントロピーによる理解
チップの授受がランダムに生じると、初期分布の情報が失われ、エントロピーが増大していくのではと考えました。そこで、エントロピー増大の視点からボルツマン分布になることを検証していきます。
人でチップ枚を授受したとき、チップが枚の人が人いるとします。この系のエントロピーは
と表されます。上記の仮説が正しいとすると、繰り返し計算する過程でエントロピーの時間変化が揺らぎながら単調増加する様子が観察されるはずです。以下のコードを実装してみます。
import numpy as np
import matplotlib.pyplot as plt
import random
def initial_distribution(num_people, num_chips):
"""
チップを初期状態としてランダムに分配します。
"""
boxes = np.zeros(num_people, dtype=int)
for _ in range(num_chips):
target_box = random.randint(0, num_people - 1)
boxes[target_box] += 1
return boxes
def give_and_take(boxes):
"""
2人をランダムに選び、片方からもう片方へチップを1枚渡します。
"""
num_people = len(boxes)
new_boxes = boxes.copy()
giver_A, receiver_B = random.sample(range(num_people), 2)
if new_boxes[giver_A] > 0:
new_boxes[giver_A] -= 1
new_boxes[receiver_B] += 1
return new_boxes
def calculate_entropy_per_particle(boxes_array):
"""
系全体のエントロピー(粒子あたり)を計算します。
"""
# 2D配列を1Dに平坦化
flat_boxes = boxes_array.flatten()
total_particles = len(flat_boxes)
# 各チップ数を持つ粒子の人数(n_i)を効率的に数える
_, counts = np.unique(flat_boxes, return_counts=True)
# エントロピーを計算
# S/N = log(N) - (1/N) * Σ(n_i * log(n_i))
entropy = np.log(total_particles) - (1/total_particles) * np.sum(counts * np.log(counts))
return entropy
# --- シミュレーションのパラメータ設定 ---
num_people = 6
num_chips = 30
num_groups = 100
num_iterations = 500
# --- シミュレーションとエントロピー計算 ---
print("エントロピーの時間変化シミュレーションを開始します...")
# 初期状態を作成
total_boxes = np.array([initial_distribution(num_people, num_chips) for _ in range(num_groups)])
# 各時間ステップでのエントロピーを記録する配列
entropy_history = np.zeros(num_iterations)
# メインループ
for t in range(num_iterations):
if (t + 1) % 100 == 0:
print(f" イテレーション: {t + 1}/{num_iterations}")
# 全グループでチップ交換を実行
for g in range(num_groups):
total_boxes[g, :] = give_and_take(total_boxes[g, :])
# 現在の系のエントロピーを計算して記録
entropy_history[t] = calculate_entropy_per_particle(total_boxes)
print("シミュレーションが完了しました。")
# --- グラフの描画 ---
print("グラフを生成しています...")
plt.style.use('seaborn-v0_8-whitegrid')
fig, ax = plt.subplots(figsize=(10, 6))
ax.plot(entropy_history, label='Entropy per Particle', color='dodgerblue', lw=1.5)
# グラフの装飾
ax.set_title('Time Series of Entropy')
ax.set_xlabel('Time (Number of Iterations)')
ax.set_ylabel('Entropy per Particle')
ax.legend()
ax.grid(True, linestyle='--', alpha=0.6)
ax.set_xlim(0, num_iterations)
ax.set_ylim(2.0, 3.5) # 元記事のグラフに合わせて設定
# グラフをファイルに保存して表示
plt.savefig('time_series_entropy.png')
plt.show()
print("\n処理が完了しました。エントロピーの時系列グラフは 'time_series_entropy.png' として保存されました。")
実装結果
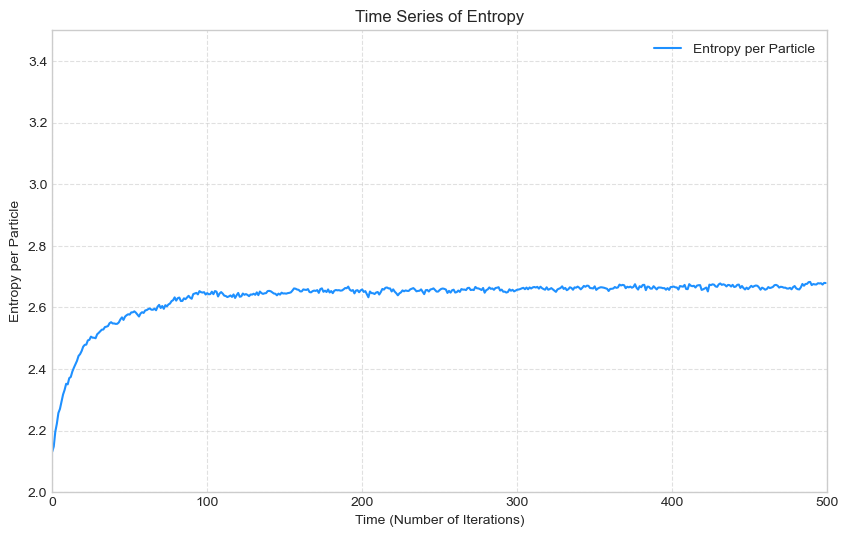
揺らぎながらも、初期状態から単調増加して、回目くらいで熱平衡状態のような状態に至ることが確かめられました。
エントロピー増大とボルツマン分布
エントロピー増大からボルツマン分布を導いてみましょう。
を最大化するのが目標です。スターリングの公式を使って変分を取り、最大値を取る条件 を適用すると、
になる必要があります。ただし、には粒子数、エネルギー量の2種類の拘束条件がかかります。
拘束条件付きの最大化にはLagrangeの未定乗数法が便利です。 と を未定乗数にして、
各 は独立だと考えて良いので、
であり、ボルツマン分布の形が出現します。このように、粒子数、エネルギーによる拘束条件のもと、エントロピーを最大化すると指数関数が登場することがわかりました。人数やチップ数を固定しつつ、チップの授受で系をかき乱し続けたら、これと同じ状況が実現し、指数関数がグラフに現れたのだと理解することができます。
まとめ
粒子数、総エネルギーを一定に保ちつつ、系の構成要素がエネルギーの授受をする環境だと、その分布がボルツマン分布に従う。